2020
 |
Riccardo Tommasi |
| Business developer |
| Webinar « Modélisation des résultats d’étalonnage et mise en application dans M-Care » : vos questions, nos réponses |
Nous nous sommes engagés à répondre à chacune des questions posées lors du webinar#6 : « Modélisation des résultats d’étalonnage et mise en application dans M-Care », qui a eu lieu jeudi 07 Mai à 10H30. Vous trouverez dans cet article l’ensemble des questions qui ont été posées via le chat et auxquelles nous n’avons pas pu répondre en live. Nous restons à votre disposition par mail pour obtenir le support de présentation ou pour toute autre précision. Découvrez aussi notre programme de formation dédié NOUVELLE DÉFINITION DE L’ÉTALONNAGE DU VIM 3 : UTILISATION DU LOGICIEL DE MODÉLISATION M-CARE.
Modélisation des résultats d’étalonnage et mise en application dans M-Care
Questions/Réponses
Question : Est-ce que ce sujet est « poussé » au niveau du COFRAC ? A ce jour, quasiment aucun laboratoire (y compris le LNE) ne suit ces exigences du VIM…
Réponse : Comme toutes les normes, le VIM est d’utilisation volontaire, chacun fait comme il le souhaite. On peut néanmoins s’émouvoir du peu d’engouement des laboratoires à mettre en œuvre cette nouvelle définition et il est fort probable qu’ils ne le feront que s’ils y sont obligés. De ce fait, c’est principalement aux clients des laboratoires de demander cette prestation car un étalonnage qui ne « regarde » que quelques points (rarement plus de 5) n’a pas vraiment d’intérêt. Peut-être que le COFRAC (ou une organisation internationale de niveau supérieur) se saisira un jour de cette question, les industriels auraient surement aussi intérêt à le pousser dans ce sens.
Question : Les laboratoires accrédités vont-ils devoir faire évoluer leur constat/certificat ?
Réponse : S’ils voulaient bien suivre la définition du VIM, ou si les clients, voire le COFRAC, l’exigeaient (enfin !), la réponse serait oui. Les certificats d’étalonnage actuels ne sont pas compatibles avec les exigences de la modélisation qui nécessite de décomposer les incertitudes actuelles données sur les écarts en incertitude sur les X – Etalons – et sur les Y – Valeurs indiquées. C’est donc plus surement au marché (les industriels) de comprendre ce qu’ils achètent et, par conséquence, de bousculer un peu les choses pour ne plus se contenter de quelques points sans intérêt … Nous redisons ici qu’il n’y a aucun surcoût à faire cette modélisation puisque toutes les informations nécessaires sont connues et que des logiciels existent et sont gratuits (M-CARE et REGPOLY).
Question : Le module « étalonnage » d’Optimu permet-il de faire cette modélisation ?
Réponse : Le logiciel M-CARE, développé par Deltamu, permet de dialoguer avec les logiciels d’étalonnage, donc avec Optimu. A ce jour, personne ne nous a encore formellement demandé d’activer cette fonctionnalité. Dès que le marché le demandera, nous serons en mesure de le faire rapidement.
Question : De tels résultats d’étalonnage (modélisation) deviennent-elles une exigence normative ?
Réponse : Les normes sont d’utilisation volontaire. Les industriels font donc ce qu’ils veulent sauf lorsqu’ils s’engagent à la respecter. Pour s’engager, il faut que quelqu’un le demande … Il semble clair que le mutisme des acteurs du marché depuis 12 ans n’est pas de bon augure pour que ce soit les laboratoires prestataires, voire même le COFRAC, qui poussent à aller dans cette direction. Mais les clients de ces acteurs ont leur mot à dire et peuvent demander, voire exiger, cette seconde étape lorsqu’ils payent un étalonnage. Le marché s’adaptera alors à cette nouvelle exigence des clients, surtout dès qu’un client se donnera la peine de le demander. Les industriels en général ne s’adaptent-ils pas aux exigences de leurs clients sous peine de les voir partir à la concurrence ?
Question : Serait-il possible d’avoir un exemple concret d’application de l’algo GGMR ?
Réponse : Vous pouvez télécharger le logiciel M-CARE sur le site du Collège Français de Métrologie. Vous pouvez ensuite faire tous les exemples que vous voulez. Vous pouvez même comparer les modèles obtenus avec les différents algorithmes disponibles (OLS, WLS, GLS et GGMR). Evidemment, pour voir « travailler » l’algorithme GGMR, il faut paramétrer les incertitudes en X et en Y avec M-CARE, pour que la matrice de variances-covariances des données d’entrée soit calculée (automatiquement) et disponible.
Exemple :
| X | Y | uX (σ) | uY (σ) |
| 1 | 0,943 | 0,1 | 0,025 |
| 2 | 2,053 | 0,1 | 0,04 |
| 3 | 2,993 | 0,1 | 0,06 |
| 4 | 4,053 | 0,1 | 0,08 |
| 5 | 4,85 | 0,1 | 0,15 |
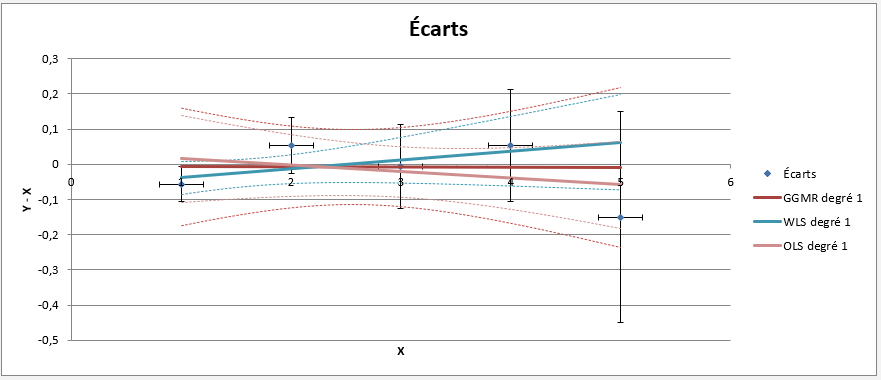
Selon la méthode choisie, les résultats sont différents :
- OLS : ne tiens pas compte de la différence d’incertitude, elle donne la même importance au résultat du point 1 et du point 5.
- WLS : donne plus de poids au point 1, mais ne prend pas en compte l’incertitude en x qui est importante.
- GGMR : prend en compte l’ensemble des informations. C’est bien sûr la modélisation la plus exacte.
Question : y = x mais qu’est-ce que x et qu’est-ce que y ?
Réponse : Nous appelons conventionnellement Y les valeurs indiquées par l’instrument de mesure en cours d’étalonnage et X les valeurs des étalons.
Question : Qu’est-ce qui varie dans la simulation ?
Réponse : La simulation, qui permet de dessiner l’ellipse de signature pour savoir s’il est nécessaire, ou pas, de corriger l’instrument de mesure, est réalisée en faisant varier les X possibles (étalons) et les Y possibles (Valeurs indiquées) à partir des incertitudes paramétrées dans M-CARE. Il s’agit en fait de simuler des résultats d’étalonnage qu’on obtiendrait avec un instrument parfait sur les points d’étalonnage qu’on fait d’habitude.
Question : Comment construire ce nuage de points puisque l’appareil n’est pas parfait ?
Réponse : Cf Question « Qu’est-ce qui varie dans la simulation ? ». Vous pourrez trouver des informations plus explicites dans cet article qui était en support d’une conférence que nous avons présentée dans le cadre du Congrès International de Métrologie à Lyon, en 2007 : http://www.deltamu.com/fr/Publications/TelechargerArticlePublication/15
Question : Finalement, en tant que client comment je vais exploiter un certificat d’étalonnage ?
Réponse : Comme nous l’avons dit, il n’est pas possible de mettre en œuvre la méthode GGMR pour modéliser des résultats d’étalonnage sans connaitre la matrice de variances-covariances entre les données d’entrée. Cette matrice ne peut pas être calculée avec l’information concernant l’incertitude d’étalonnage portant sur l’écart entre la valeur mesurée et la valeur étalon. C’est au laboratoire de faire cette modélisation, sauf s’il vous donne ses incertitudes sur les X et sur les Y, avec quelques informations complémentaires (caractère HO/LO des causes d’incertitudes)
Question : Qu’est-ce-que l’écart type de prédiction sur yi donné par DROITEREG ? La « prédiction » est-elle différente de la « prévision » du modèle ?
Réponse : La valeur « sey », appelée « L’erreur type pour la valeur y estimée » dans la notice Excel, est en fait l’écart-type des résidus au modèle. Si les hypothèses d’utilisation de la méthode des moindres carrés sont respectées, cet écart-type permet de définir une zone autour de la droite où l’on peut raisonnablement trouver un point mesuré y pour un x donné, d’où son appellation par Excel « L’erreur type pour la valeur y estimée ». Attention, cet écart-type est calculé en tenant compte du nombre de degrés de liberté (DDL) qui est lui-même fonction du degré du polynôme de modélisation (DDL = Nombre de points – (Degré du polynôme +1)). On ne fait pas de différence entre « prédiction » et « prévision ». L’idée est toujours de retrouver une valeur X (ou Y suivant le sens utile du modèle) à partir de Y (ou de X) mais attention à évaluer également l’incertitude sur la prévision (ou prédiction) à partir des incertitudes sur les coefficients, de la variance des résidus, en appliquant la loi de propagation du GUM …
Question : Est-il intéressant d’utiliser la modélisation WLS dans le cas où l’on connait les incertitudes en y qui seraient toutes identiques
Réponse : Non, aucun intérêt car la méthode WLS applique une pondération égale à l’inverse de la variance sur chaque donnée Y pour faire ses calculs. Si tous les Y ont la même incertitude, ils auront la même pondération et le résultat donnera ce que donne la méthode OLS.
Question : Est-ce que le choix de la méthode des moindres carrés doit être discuté avec le client ?
Réponse : Non, nous ne le pensons pas. La méthode à choisir ne dépend pas d’un avis mais du contexte. Or, dans un contexte d’étalonnage, il y a toujours des incertitudes en X, toujours des incertitudes en Y et souvent des incertitudes qui varient en fonction du niveau (plus X est grand, plus l’incertitude sur X est grande). Par ailleurs, il existe très souvent des covariances entre les points d’étalonnages (couples (X,Y)) qui se suivent et il peut en exister sur un point d’étalonnage entre l’étalon et le résultat de mesure (entre le X et Y). Fort de ce constat, seule la méthode GGMR (dans les méthodes des moindres carrés) est, dans la plupart des cas, acceptable.
Question : M-CARE a-t-il été mis à jour pour être compatible avec les dernières versions d’Office ?
Réponse : Malheureusement non. Si votre version ne fonctionne pas, vous pouvez nous contacter chez Deltamu, nous pourrons probablement vous aider.
Question : Bonjour, à partir de quel ratio peut-on dire que les incertitudes sur les X sont négligeables ?
Réponse : Il n’y a pas de règle toute faite mais on peut partir sur l’idée qu’un ratio inférieur à 10% (en variance, attention !) permettrait d’appliquer l’OLS, mais attention aux conditions sur la même incertitude sur tous les Y et l’absence de covariance entre les Y !
Question : Comment appelle-t-on l’estimateur de l’incertitude type ?
Réponse : Une incertitude type représente la résultante du mélange de tous les écarts types des causes qui participent au processus de mesure. Dans tous les cas, les écarts types des causes élémentaires ne sont que des estimateurs des écarts types « vrais » sous-jacent (il n’est pas possible de connaitre le « vrai » écart type sur la base d’un échantillon, quelle que soit sa taille). La résultante de ces estimateurs est donc elle-même une estimation mais n’a pas de nom spécifique pour la distinguer d’une valeur « vraie ».
Question : Pouvez-vous nous donner un exemple d’une lecture d’un certificat d’étalonnage : une balance de mesure
Réponse : Ce serait bien trop compliqué dans cet article. Nous vous invitons à télécharger M-CARE puis de revenir vers nous si vous n’arrivez pas au bout de l’exercice, nous vous aiderons. Découvrez aussi notre programme de formation dédié NOUVELLE DÉFINITION DE L’ÉTALONNAGE DU VIM 3 : UTILISATION DU LOGICIEL DE MODÉLISATION M-CARE.
Question : Quelle est la différence entre valeur vraie et valeur la plus probable ?
Réponse : La valeur vraie reste le Graal que nous ne pourrons jamais connaitre. La valeur mesurée est, quant à elle, une réalisation d’une variable « rendue » aléatoire en grande partie (car il y a aussi des causes d’incertitudes propres à l’entité mesurée elle-même : l’incertitude définitionnelle notamment) à cause des facteurs imparfaits et aléatoires qui participent à la réalisation de la mesure. Cette valeur mesurée est entachée d’une erreur inconnue et c’est pourquoi on évalue l’incertitude de mesure qui représente en quelque sorte l’erreur de mesure la plus grande qui risque de s’être produite au moment de la mesure.
La valeur la plus probable est une valeur qui peut être calculée en tenant compte de la valeur mesurée, de l’incertitude de mesure mais aussi de la connaissance « a priori » de l’entité mesurée. On parle alors d’inférence bayésienne. Il s’agit en fait d’un post traitement qui tient compte de toutes les informations pour avoir une meilleure évaluation de la valeur vraie.
Dans le cas d’une modélisation, on estime que la valeur la plus probable est celle donnée par le modèle ce qui ne nous empêche pas de vérifier si l’écart entre le modèle et la valeur mesurée peut ou non s’expliquer du fait de l’incertitude sur Y.
Ce point est développé sur notre blog dans l’article suivant : http://www.smart-metrology.com/blog/2015/05/bayes-ou-une-facon-si-enthousiasmante-de-reconsiderer-les-mesures/
Question : Vous dites Y = b0 + b1X. Ce ne serait pas plutôt Y = aX + b ?
Réponse : Cette question revient souvent. En fait, à l’école, on a tous appris Y = aX + b ou … Y = a + bX, ce qui crée une confusion. Par convention, nous avons décidé d’utiliser la lettre b pour les coefficients du polynôme et on met en indice la puissance de X. Ainsi, b0 est le coefficient constant (X0 = 1), ou ordonnée à l’origine, b1 la pente et ainsi de suite pour les polynômes de degrés supérieurs.
Question : Existe-t-il une théorie (une norme ou autre) qui indique le nombre de points du modèle en fonction du nombre de points de consigne ?
Réponse : Il est nécessaire d’avoir au minimum un nombre de points de consigne supérieur ou égal au degré du polynôme +2, en tout cas pour obtenir une évaluation des incertitudes sur les paramètres (Excel retourne 0 sur les incertitudes s’il n’y a pas assez de points car il ne peut pas calculer l’écart-type des résidus). En revanche, et comme toujours en statistique, moins j’ai d’informations, plus j’ai de doutes. Autrement dit, l’incertitude sur les coefficients du modèle sera d’autant plus importante que le nombre de points sera petit. A noter qu’Excel retourne des coefficients même lorsque le nombre points n’est pas suffisant mais ils n’ont pas vraiment de sens, ils sont choisis, en fait, dans une multitude de possibilités différentes.
Question : Est-ce au niveau d’un certificat d’étalonnage, l’incertitude de mesure élargie doit être émise d’une manière évidente ?
Réponse : En théorie oui, une mesure n’a aucun sens si elle n’est aps accompagnée d’une incertitude. Pour els laboratoires accrédités, cette évidence est forcément respectée mais on peut imaginer des contextes dans lesquels on « l’oublie ». Il faut alors s’interroger sur l’intérêt du document…
La vidéo intégrale du webinar est disponible sur notre chaîne youtube!

Souhaitez-vous rester en contact avec nous? Suivez-nous sur les réseaux sociaux et/ou inscrivez-vous à notre Newsletter!



