Une nouvelle intelligence est née …
Quel bonheur de lire ce titre prometteur dans le numéro 1198 de Science&Vie (Juillet 2017) ! Quel bonheur surtout d’avoir touché du doigt, tout récemment, ce que signifiait cette affirmation dans le monde industriel …

En 2015, Deltamu a lancé le site mesuronsbienlebigdata.com car nous sentions bien le mouvement alors balbutiant de l’intérêt du Big Data pour la compétitivité industrielle. Cette date n’est pas vraiment très éloignée mais il s’est, depuis, passé tellement de choses : les concepts de digitalisation des entreprises, continuité numérique au service de l’industrie du futur, … L’impact de l’Intelligence Artificielle, nom générique qui couvre l’ensemble des nouveaux outils algorithmiques, commence également à faire l’objet de communications et d’interrogations.
Deltamu oeuvre depuis 2015 pour faire connaitre ces nouveaux outils et, bien sûr, les nouveaux enjeux de la métrologie dans ce monde qui se dessine. Le projet AGORA, porté dans sa dimension « formation initiale » par les écoles d’ingénieurs clermontoises SIGMA Clermont et ISIMA, a pour objectif de former des data scientists pour l’industrie. Deltamu, parmi les initiateurs de ce projet, s’engage parallèlement dans une nouvelle prestation.
Convaincue que cet horizon est désormais inéluctable, Deltamu fédère un consortium* dont l’objectif est d’offrir une solution pertinente à l’accompagnement des industriels dans leur transformation digitale, en consolidant tous les aspects :
- structure informatique ;
- consolidation des données ;
- modélisation prédictive ;
- pilotage de procédés ;
- véracité des données ;
- accompagnement à l’appropriation par les équipes opérationnelles.
De l’idée à la concrétisation, il n’y a qu’un pas et le consortium vient de présenter ses résultats et préconisations au premier industriel qui lui a fait confiance. Quel plaisir de voir, dans les yeux des nombreux interlocuteurs présents qui représentaient tous les services de l’entreprise une énorme surprise quant à la capacité de prédiction que nous avons démontrée sur un procédé industriel compliqué. Quand la direction générale, la direction opérationnelle, la direction financière, les responsables de production, le responsable qualité, le responsable métrologie sont séduits, c’est bon signe !
Estimer, à partir des paramètres d’entrée, la probabilité de conformité finale sans connaitre le modèle mathématique sous-jacent et vérifier ladite probabilité sur des données historiques existantes leur a paru, et c’est bien normal, plus que prometteur. Prédire la conformité finale revient à maîtriser le pilotage d’un procédé pour qu’il produise conforme « du premier coup, et à chaque fois » ! Une forme de Graal pour l’industrie …
Cette « promesse » ne va pas sans quelques efforts. Le premier est évidemment de rassembler toutes les données disponibles, des automates programmables jusqu’au contrôle final en passant par l’ensemble des supervisions et de la gestion de production, dans un « datalake » représentant le patrimoine numérique de l’entreprise.
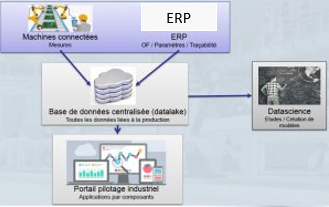
Infrastructure du système d’informations
Le bloc « Data Science » du schéma ci-dessus représente tout le travail de recherche de valeur dans les données disponibles. L’objectif est de trouver des modèles prédictifs qui permettent d’anticiper la conformité de la production, donc les clefs du pilotage des procédés.
Si tous les ingénieurs de production ont l’habitude des modèles analytiques (de la forme Données de sortie = F[Données d’entrées], issue généralement des plans d’expériences), il faut désormais s’adapter à des modèles différents, non analytiques, qui se présentent sous la forme d’algorithmes auto-apprenants. Comme leur nom l’indique, ces algorithmes (cette nouvelle intelligence) apprennent tout seuls, sur la base des informations antérieures. Ils « s’ajustent » automatiquement, un peu comme une table de mixage qui se réglerait toute seule dans une salle donnée en « écoutant » quelques morceaux tout en connaissant, préalable indispensable, les attentes des auditeurs en terme de qualité auditive.
Dans le dossier de Science&Vie de Juillet 2017, un exemple nous explique qu’un algorithme a appris à « deviner » la présence d’un lion sur une photo (rappelons que vu d’un ordinateur, une image est une collection de 0 et de 1 !), non pas via la couleur de l’animal ou la forme de sa crinière, ce qui serait déterminant pour un humain, mais à partir d’une particularité des yeux des lions qu’il a su découvrir en exploitant une bibliothèque de photos.
Cet exemple montre bien la capacité des algorithmes à trouver des éléments différenciants qui ne nous apparaissent pas naturellement. Combien de tels « signaux faibles » se cachent encore dans les procédés industriels de production et posent des problèmes en impactant négativement la performance des entreprises à cause de rebuts ou de durées de vie altérées ?
Le Big Data et l’Intelligence Artificielle permettront, c’est quasi-certain, de mieux comprendre, donc de mieux maîtriser, des phénomènes encore compliqués à appréhender avec nos outils conventionnels. C’est certain, le jeu en vaut la chandelle ! D’aucuns n’hésitent d’ailleurs pas à l’affirmer : « Do it or die » !

Une fois les modèles prédictifs opérationnels, il devient nécessaire d’offrir aux utilisateurs une interface simple et intuitive qui permettra de piloter les procédés de façon optimale. Et là encore, les spécialistes de la donnée disposent d’outils permettant de réaliser simplement et rapidement de telles interfaces. Dédiées à chaque contexte, et capables de réapprendre autant que de besoin pour s’améliorer encore et encore, elles s’inscrivent dans le cercle vertueux promu par les référentiels qualité type ISO 9001. Comment ne pas voir, dans ce « Big Data et ses algorithmes », la fameuse roue de Deming (PDCA) ?
Notre consortium se propose d’accompagner les industriels sur ce chemin, par les outils d’aujourd’hui et de demain (Intelligence Artificielle), sans négliger ceux d’hier (Par exemple le Lean Management). Nous connaissons bien sûr la résistance au changement que peut susciter une telle approche tant certaines croyances risquent d’être remises en cause. Et puisqu’il est légitime que les Hommes de l’entreprise s’approprient ce changement, nous intégrons cette dimension essentielle.
Pour avoir vu fonctionner concrètement les algorithmes, j’ai pu mesurer toute l’importance de la métrologie dans ce nouveau monde. Si nos tolérances actuelles ont été établies de façon empirique à partir de nos observations, et sans tenir compte des incertitudes de mesure, elles ne pourront être remises en cause de façon pertinente pour plus d’efficience que si les données disponibles sont fiables, c’est à dire dont la Véracité est garantie (4ème V du Big Data). Que ce soit sur les données d’entrée (pilotage) ou sur les données de sortie (conformité), les mesures doivent être le plus proche possible de la réalité. Et la conformité des instruments à une norme et à une date n’y suffisent pas ! Un récent article de ce blog décrit bien les nouveaux enjeux …
A ce jour, il est impératif de retenir que les algorithmes prédictifs ne se règlent bien que si les données d’entrée et de sortie sont fiables. Pour « apprendre » (on parle souvent de « Machine Learning » ), ils doivent disposer de données fiables mais surtout un historique de données antérieures fiables.
Et puisqu’il est inexorable que ce nouveau PDCA s’installe finalement dans les entreprises car il est plus « prédictif » grâce à la possibilité de découvrir des signaux faibles, le métrologue doit sans délai revoir son rôle et s’intéresser aux mesures, plutôt qu’aux instruments de mesure !
* en collaboration avec les sociétés Pyramis, Phimeca et Agaetis (membres du e-cluster Auvergne Efficience Industrielle)
PS : Pour plus d’informations sur le consortium et ses prestations, vous pouvez contacter le service commercial de Deltamu, au 04 73 15 13 06
